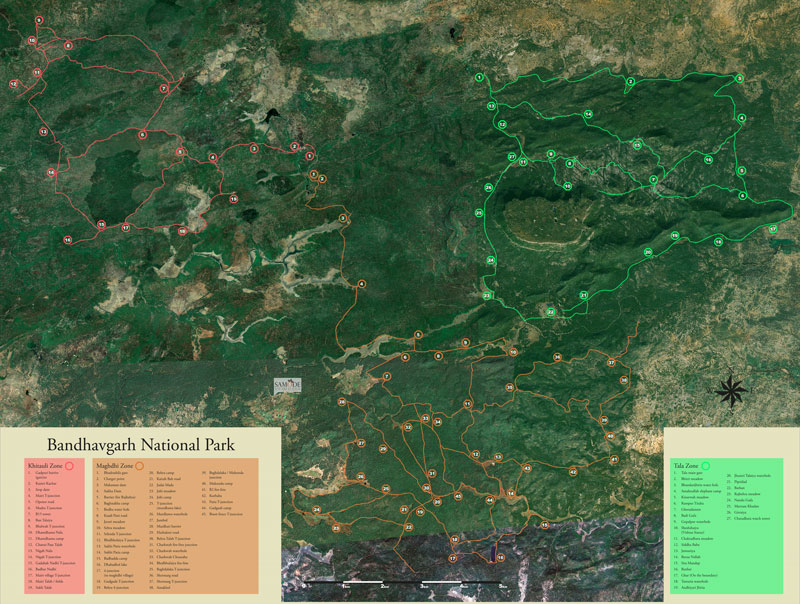
Immensely private, the 35 acres of Samode Safari Lodge offer epic views and prime position amidst a vast swath of wildlife rich forest of Bandhavgarh. Overlooking the Reserve’s buffer zone, the lodge’s design is inspired from the neighbouring Mardari village to seamlessly blend into the region’s landscape.
Understated luxury, service that is warm and personal and yet unintrusive, curated meals, Samode Safari Lodge is inspired by iconic Indian royal expeditions of the Rajputana yesteryears.
![]()

Our immensely private lodge offers a luxury safari adventure in an evocative natural setting.
Conscious of overburdening the land, we chose to locate ourselves away from the tourist hospitality zone in the quietness of the Mardari village. A stone’s throw from the core forest, our lodge is located a mere 25 minutes drive through thick wilderness to reach the Khitauli, Maghadi and Tala gate
Committed to rewilding the 30 acres that we are located in, the lodge was designed with a deep respect for the region’s environmental and cultural conservation.
![]()


